数据库服务
数据库解决方案
关系型数据典型代表(Amazon RDS)
非关系型数据库(Amazon DynamoDB)
数据库缓存
数据库迁移工具
数据库服务
SQL和NoSQL
OLTP(事务类数据库),OLAT(分析性数据库,大批量的数据分析)
SQL(SQL语句查询方便,数据格式较为固定)
RDS
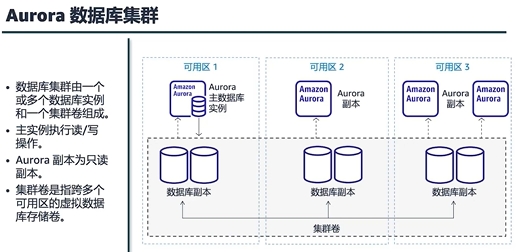
Aurora
ReadShift(数据仓库)
NoSQL(大吞吐,低延迟,灵活性,不限于表结构,水平扩展)
MongoDB(DocumentDB)
DynamoDB(键值对数据库,高性能,低延迟,大吞吐)
缓存数据库(ElastiCache,基于键值对的,托管的Redis,MemCached解决方案)
基于Redis的持久化数据库(MemoryDB)
高吞吐的水平扩展的(KeySpace,兼容开源的Apache Cassandra,非关系型数据)
TimeStream(时序类的数据库,IoT物联网,传感器,监控设备上的数据)
Neptune(图形数据库,graph database,social network,recommendations,关系分析)
区块链底层的数据库(不可删除和修改,Quantum Ledger)

Amazon RDS
提供六种常用的数据库引擎供您选择,包括
Amazon Aurora
(兼容MySQL和PostgreSQL)
serverless方案
底层用什么实例,多大容量自行调整
最小实例切换到最大实例毫秒级
无感知的使用数据库
无服务器的方式按实际使用量收费
数据库集群方案,吞吐量比mysql和PostgreSQL高
PostgreSQL
MySQL
MariaDB
Oracle Database
Microsoft SQL Server
扩展读的场景
水平扩展,建立更多的数据库,创建只读副本,将主数据异步复制到副数据库(主从时间差,replica lag)
数据库安全
静态数据加密
安全的密钥管理器(KMS,根密钥,嵌套加密)
Amazon DynamoDB
可扩展的NoSQL数据库,键值对数据库
超大的吞吐,超低的延迟,水平扩展(数据分区,按key进行分区,分区键,复合主键,排序键可选,其他属性可有可无,没有不用存储,可以和json格式进行类比)
无服务器的服务,不需要创建数据库实例,按需扩展(费用比较高),流量模型有清晰的了解(预置的方式,采用弹性伸缩的方式进行调整)
可以通过API创建数据
primary key,attributes
最终一致性,保证立刻复制到其他副本(0.5个读取容量单位)
强一致性,RCU (Read Capacity Unit):1 RCU = 每秒支持 1 个强一致性读取 或 2 个最终一致性读取,对于 4 KB 大小的数据。
全局表,全球不同的区域创建某一张表的副本,读取和写入,全球多副本
数据库缓存
两种方式
延迟加载
更新数据库同时写到缓存里,缓存存储过多的数据,成本较高
性能优先还是成本优先
管理缓存
TTL,变更频繁的数据TTL短一点
Amazon ElastiCache
MemCached
Redis