可靠性
可靠性支柱重点关注工作负载在预期情况下能够正确且一致地执行预定功能的能力。这包括能够在工作负载的整个生命周期中运行和测试工作负载。
可靠的工作负载必须能够应对需求或要求的变化,且必须设计为能检测故障并自动修复。
在云中
在云中,种种限制将不复存在。这使我们能够采用这些设计原则来构建和运营可靠的云原生架构。 测试破坏范围之外的情况,从而确保恢复过程自动执行且成功完成
提供多个资源来响应请求,这样,任何单个组件中的故障往往都有同级组件可以介入并承担负载
使用横向扩缩来满足需求
自动变更控制,通过代码对环境进行变更时,采用我们应用于应用程序代码的相同最佳实践
弹性的责任共担模式
云中工作负载的可靠性取决于多个因素,其中最主要的是弹性
AWS 负责管理云的弹性
AWS 负责运行 AWS 云中提供的所有服务的基础设施的弹性。此基础设施由运行 AWS 云服务的硬件、软件、网络和设施组成。
AWS 组件可抽离低级别故障,例如硬盘和电源故障。AWS 服务是使用冗余等最佳实践构建的。
AWS 将通过 Service Health Dashboard 以透明方式与您通信
客户负责管理云中的弹性
您的责任取决于您选择的 AWS 云服务。这决定了您在履行弹性责任时必须完成的配置工作量。 使用 AWS 工具和服务架构和构建可靠的解决方案。作为客户,您有责任对系统的以下方面进行管理,以实现云中的弹性。
联网、配额和限制
变更管理和运营弹性
可观测性和故障管理
工作负载架构
关键基础设施的持续测试

设计原则
利用可靠性支柱设计原则指导您在 AWS 云中实现可靠的工作负载运营。
五个可靠性设计原则。
自动从故障中恢复
通过监控工作负载的关键性能指标 (KPI),您可以在超出阈值时运行自动化。KPI 评估的应该是商业价值,而非服务运营的技术层面。这可以自动发出通知和跟踪故障,并自动执行可解决故障或修复故障的恢复过程。
对于许多故障类型,终止并更换 Amazon Elastic Compute Cloud (Amazon EC2) 实例是一个不错的方法。
配置 AWS Auto Scaling 并执行适当的运行状况检查来实现这一点。
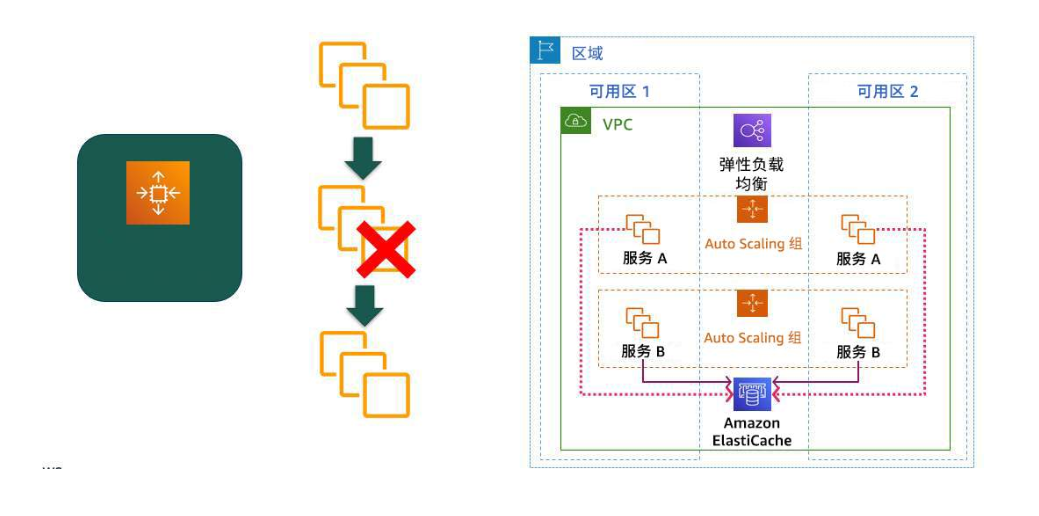
考虑设计无状态应用程序。这种设计不需要以前的操作记录就能成功执行。在以下示例中,一个应用程序在两个可用区中运行。服务 A 和服务 B 在 Auto Scaling 组的 EC2 实例中运行。为了支持实例更换,该应用程序使用 Amazon ElastiCache 作为中央数据存储。
在应用了面向恢复的方法的系统中,多种类型的故障都将映射到同一恢复策略。实例可能由于硬件故障、操作系统错误、内存泄漏或其他原因而出现故障。
与其针对每个原因制定自定义补救措施,不如将任何原因都视为实例故障,终止实例,然后更换实例。
测试恢复过程
本地部署环境中经常会进行测试,证明工作负载可在特定场景中工作。通常不会将测试用于验证恢复策略。在云中,您可以测试工作负载的故障情况,还可以验证恢复程序。
您可以使用自动化功能来模拟不同的故障或重新创建此前导致故障的场景。这种方法公开了故障路径,您可以在实际出现故障场景前测试和修复这些路径,从而降低风险。
AWS Fault Injection Simulator (AWS FIS) 是一项完全托管式服务,用于在 AWS 上运行故障注入试验,以便更加轻松地改进应用程序的性能、可观测性和弹性。
当您从控制台创建混沌试验时,AWS FIS 会自动为您创建一个可以重用的模板。
当您开始试验时,AWS FIS 会在您的 AWS 资源上注入真实的故障。
最佳实践是让 Amazon CloudWatch 警报监控您的 AWS 资源和工作负载。定义一些停止条件,用于在其状态发生变化时自动停止试验。您可以将自己的监控解决方案与 Amazon EventBridge 集成,以启动停止条件。
横向扩展以提高工作负载的整体可用性
使用多个小型资源代替一个大型资源,降低单点故障对整体工作负载的影响。将请求分配至多个小型资源,以免出现相同的故障点。
在 AWS 云中,垂直扩展指的是用更大的实例类型来替换实例。可用的大型实例的数量要与之前小型实例的数量保持一致。
对于水平扩展,可以在总池中添加更多相同类型的实例。这可以提供相同的计算能力,但提高了可用性。如果您在有四个 c5.xlarge 实例的池里失去一个实例,您的容量会减少到 75%。比较一下在一组八个 c5.large 实例中的情况。相同的处理能力会分布在更多实例上。一个实例出现故障只会使计算容量减少到 87.5%。

无需猜测容量
本地部署工作负载出现故障的常见原因是资源饱和,也就是对工作负载的要求超出了工作负载容量(这通常是拒绝服务攻击的目标)。
在云中,您可以监控需求和工作负载利用率,并实现添加或删除资源的自动化,保持满足需求的最佳水平,避免供应过度或不足。
Auto Scaling 可应用于 Amazon EC2、容器任务、DynamoDB 吞吐量等。它可以基于需求自动预置您的容量。确定表明需求的指标或关键绩效指标 (KPI)。避免只依赖 CPU 指标或内存指标。
查看以下 Amazon EC2 示例,了解 Auto Scaling 的好处。
在下图第一个示例中,Diego 和 Ana 是运营工程师,他们在考虑如何满足需求并进行扩展。Diego 认为他们需要添加四个实例,而 Ana 认为只需要两个。没有人想在进行容量规划时猜测容量。这种方法需要大量手动工作来横向扩展。
在下图第二个示例中,我们复制了第一个示例中的相同 EC2 实例集和负载均衡器,并引入 Auto Scaling。首先,将实例放在一个 Amazon EC2 Auto Scaling 组中。然后,引入一个 Amazon CloudWatch 警报来监控 ELB 请求。达到阈值后,CloudWatch 会指示 Auto Scaling 组增加容量。这里增加了两个 EC2 实例来帮助承担流量负载。

管理自动化方面的变更
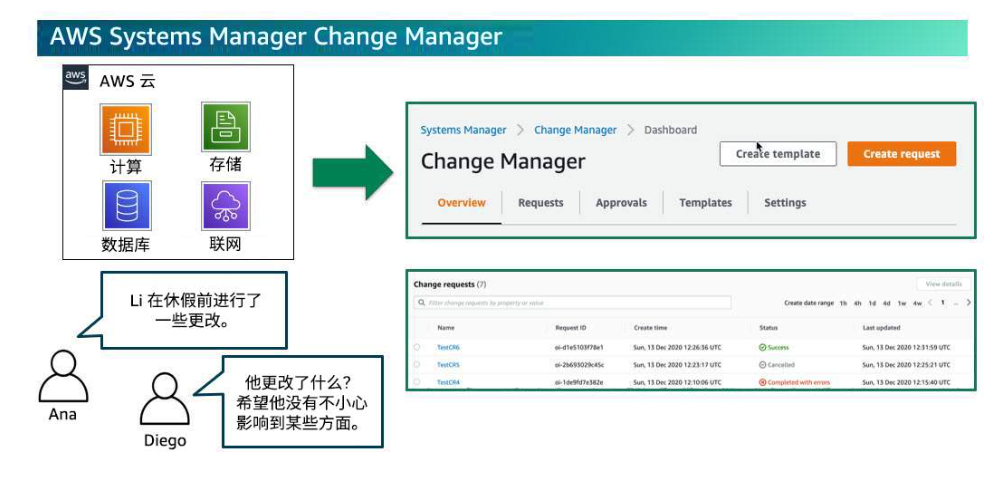
基础设施变更应通过自动化操作完成。需要管理的变更包括对自动化的变更,然后可对其进行跟踪和审核。
报告和审计是变更管理的重要组成部分。为此,可以考虑使用 AWS Systems Manager Change Manager 之类的工具。
自动化变更控制可降低手动错误的风险、提高速度并确保一致性。此外,还可以轻松地对其进行跟踪。
最佳实践
为了实现可靠性,需要从基础入手。使用最佳实践设计服务配额和网络拓扑结构,以适应您的工作负载。 分布式系统的工作负载架构设计应能够防止和减少故障。工作负载必须能够应对需求或要求的变化,且必须设计为能检测故障并自动自行修复
云可靠性有四个最佳实践领域:
基础
管理服务配额和限制
基于云的工作负载架构具有服务配额(也称服务限制)。这些配额是为了防止意外预置超出您需要的资源,并限制 API 操作的请求速率,以防止服务被滥用。此外还存在资源限制,如光纤传输速率或物理磁盘的存储量。
规划网络拓扑结构
工作负载通常处于多环境中。其中包括多个(可公开访问和私有的)云环境和现有的数据中心基础设施。计划必须考虑各种网络因素,例如系统内和系统间的连接、公有 IP 地址管理、私有 IP 地址管理和域名解析。
如果使用基于 IP 地址的网络构建系统,规划网络拓扑和寻址时必须预测可能发生的故障,以适应未来的增长以及与其他系统和其他网络的集成。
借助 Amazon Virtual Private Cloud (Amazon VPC),您可以在 AWS 云中预置一个隔离的私有部分,从而在虚拟网络中启动 AWS 资源。
工作负载架构
设计工作负载服务架构
使用面向服务的架构 (SOA) 或微服务架构来构建高度可扩展和可靠的工作负载。面向服务的架构 (SOA) 是一项通过服务接口使软件组件可重用的实践。微服务架构进一步让组件规模更小、更简单。
选择工作负载划分方式
构建注重特定业务领域和功能的服务
按 API 提供服务合同
设计可防止故障的分布式系统交互
分布式系统依赖通信网络实现服务器和服务等组件互联。尽管此类网络中存在数据丢失或延迟,您的工作负载仍然需要保证可靠运行。分布式系统组件的运行不应对其他组件或工作负载产生负面影响。这些最佳实践可防止故障并缩短平均故障间隔时间 (MTBF)。
确定所需的分布式系统类型
实现松散耦合的依赖关系
进行持续的工作
使所有响应都具有幂等性
设计可减少故障或容错的分布式系统交互
这些最佳实践使工作负载能够承受压力或容错,能更快地从故障中恢复并减轻此类损害的影响。其结果是缩短平均修复时间 (MTTR)。
实施优雅降级,将适用的硬依赖关系转换为软依赖关系
限制请求速率
控制和限制重试调用
快速故障和队列限制
设置客户端超时
尽可能实现服务无状态化
使用紧急杠杆
变更管理 您必须预见和适应工作负载或其环境的变化,保证其可靠运营。变更内容包括对工作负载施加的更改,如需求的激增,还包括内部更改,如功能部署和安全补丁。
监控工作负载资源
日志记录和指标是了解工作负载运行状况的有效工具。您可以配置工作负载以监控日志和指标,并在超过阈值或发生重大事件时发送通知。监控机制能让工作负载在超出低性能阈值或发生故障时进行识别,从而自动恢复以做出响应。监控对于确保满足可用性要求至关重要。监控需要有效地检测故障。
设计可适应需求变化的工作负载
可扩展的工作负载具有弹性,可以自动添加或移除资源,因此能够在任何给定时间点与当前需求紧密匹配。
实现资源获取或扩展自动化
检测到工作负载受损时获取资源
检测到工作负载需要更多资源时获取资源。
对工作负载进行负载测试
实施更改
可控更改对于部署新功能而言是必要的,能确保工作负载和运行环境中运行已知的、经过适当修补的软件。更改不可控时,您将难以预料其效果,也将难以解决由此产生的问题
故障管理
备份数据
备份数据、应用程序和配置,满足恢复时间目标 (RTO) 和恢复点目标 (RPO) 的要求。
利用故障隔离保护工作负载
故障隔离边界将工作负载内故障的影响限制为有限数量的组件。边界以外的组件不会受到故障的影响。使用多个故障隔离边界,可以限制对工作负载的影响。
设计能抵御组件故障的工作负载
有高可用性和低平均修复时间 (MTTR) 要求的工作负载必须具备弹性架构。
测试可靠性
设计工作负载确保其具备弹性能应对生产压力后,测试是在设计完成后唯一能够确保其按照设计意图运行并具备预期弹性的手段。
由于错误或性能瓶颈可能影响工作负载可靠性,需要测试并验证工作负载是否满足功能性和非功能性要求。测试工作负载的弹性可以让您找到仅在生产中出现的潜在错误。定期进行此类测试。
规划灾难恢复 (DR)
准备好备份和冗余工作负载组件是制定灾难恢复策略的第一步。RTO 和 RPO 是您还原工作负载的目标。基于业务需求进行设置。考虑到工作负载资源和数据的位置与功能,执行相关策略,达成前述目标。中断概率和恢复成本也是帮助了解工作负载灾难恢复的商业价值的关键因素。
可用性重点关注工作负载的组件,而灾难恢复的重心在于整个工作负载的离散副本。灾难恢复和可用性的目标不同,前者注重在发生灾难问题后的恢复用时。
王忠滟